
hmk run dev
0과 1로 문자를 표현하기 본문
알다시피 컴퓨터는 0과 1밖에 이해하지 못한다.
그런데 어떻게 우리가 작성한 문자를 해석해서 명령을 실행시킬 수 있을까?
문자집합(character set)
컴퓨터가 이해할 수 있는 문자 모음
인코딩(encoding)
코드화하는 과정
문자를 0과 1로 이루어진 문자 코드로 변환하는 과정
문자 => 0 or 1
디코딩(decoding)
코드를 해석하는 과정
0과 1로 표현된 문자 코드를 문자로 변환하는 과정
0 or 1 => 문자
문자집합
아스키코드(ASCI)
- 초창기 문자집합 중 하나
- 알파벳, 아라비아 숫자, 일부 특수 문자 및 제어문자
- 7비트로 하나의 문자 표현(실제로는 8비트)
8비트 중 1비트는 오휴 검출을 위해 사용되는 패리티 비트(parity bit)
EUC-KR
- 2300여개의 한글 표현 가능
- 여전히 모든 한글을 표현하기에는 부족한 수
- 쀌, 뗅 같은 한글은 표현 불가능
언어별 인코딩을 국가마다 하게 되면
다국어를 지원하는 프로그램 개발 시 언어별 인코딩 방식을 모두 이해해야한다...
모든 언어, 특수문자까지 통일된 문자 집합을 사용하면 어떨까?
통일된 문자 집합 & 인코딩 방식이 있다면?
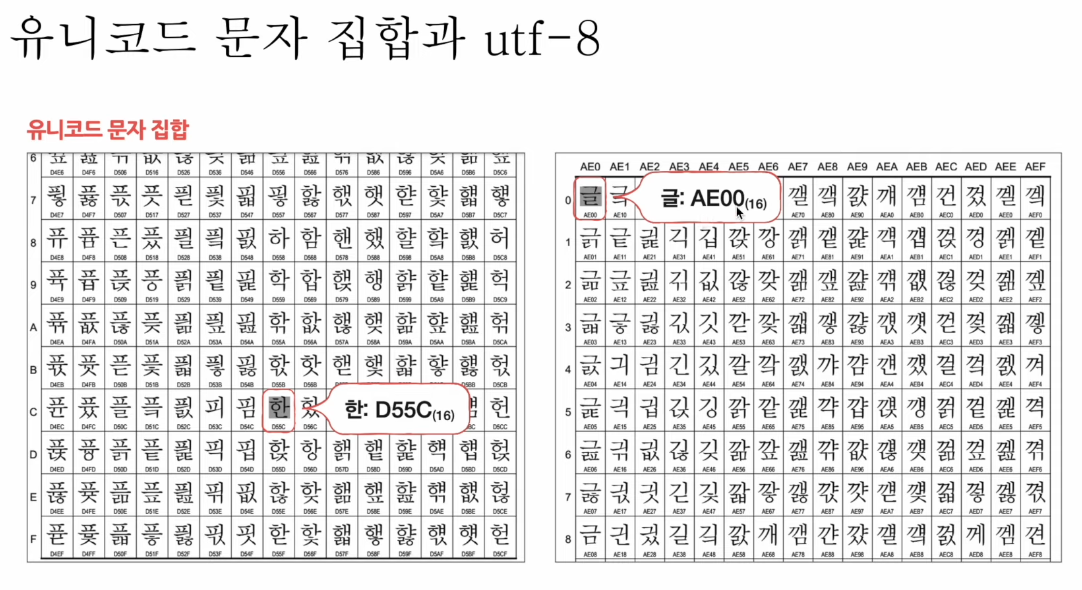
유니코드 문자 집합과 utf-8
유니코드
- 통일된 문자 집합
- 한글, 영어, 화살표와 같은 특수 문자, 심지어 이모티콘까지
- 현재 문자 표현에 있어 매우 중요한 위치
유니코드의 인코딩 방식
- utf-8, utf-16 등등..
utf-8 인코딩
가장 대중적인 인코딩 방식
- UTF(Unicode Transformation Format) == 유니코드 인코딩 방법
- 가변 길이 인코딩 : 인코딩 결과가 1바이트 ~ 4바이트
- 인코딩 결과가 몇 바이트가 될지는 유니코드에 부여된 값에 따라 다르다
utf를 binary로 변환해주는 사이트
'cs' 카테고리의 다른 글
| 빠른 CPU를 위한 설계 기법 (0) | 2024.03.02 |
|---|---|
| 소스 코드와 명령어 (0) | 2024.03.02 |
| 0과 1 (0) | 2024.03.02 |
| 컴퓨터 구조의 큰 그림 (0) | 2024.03.01 |
| 컴퓨터 구조를 알아야 하는 이유 (0) | 2024.03.01 |



